28 Mar 2021
读书笔记 - DDIA(3)
Partition
Goal with paritioning is to spread the data and the query load evenly across all nodes. If the parition is not fair, some partitions will have more data than other partitions, this is called skewed. A partition with disproportionally high load is called a hot spot.
- Partition by KeyRange: assign a continuous range of keys to a parition
- can lead to hotspot - if partition by date, all data written on this day will lead to the same partition
- Partition by Hash of key: assign range of a hash function (which turns the skewed data to evenly distributed ones) to a partition
- lost range quries ability
- Skewed Workload and Relieving the Spots
- When experience a spike in one key; this can be relieved by adding a random number in front of the hashed key
- Secondary Index -
- By Documnet - local index, every time a record writes to a parition, thie partition updates its seconday indexes

- The search however needs to go to all paritions and combine the results
- By term: global index, the second index itself is also parititoned

- The update to the global index are always async, so if you read immediately after you write, it may not be udpated yet
- Rebalancing - moving data and requests from one node to another
- DO NOT: hash mod n - you will need to move most of the data (if n changes, most of the hash mod n is going to be different)
- Fixed number of partition - when a new node is added, steal some partition from other nodes
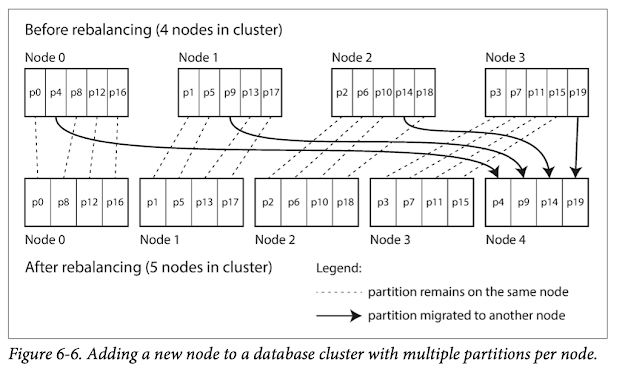
- needs to choose a node number high enough for the future
- When a partition grows exceed a configured sized, it is split into two partitions, if a lot of data is deleted and a partition shrinks below some threshold, it can be merged with an adjacent partition.
- With dynamic partition, the number of parition is proportional to the size of the dataset; with fixed number, the size of each parition is proportional to the size of the dataset;
- Fixed partition per nodes
- when a new node join, it takes random number of n paritions form nodes and take half of their data
- Request Routing:
- some service needs to stay on top to make sure a request is connected to the correct node
- Allow client to contact any node, go foward until it get to the appropriate node
- routing tier, as a partition-aware load balancer
- require the client itself to be aware of the partition and nod
Transaction
Transaction - several reads and writes grouped together into a logical unit. Either the entire transaction succeeds(commit) or it fails (abort, rollback)
-
ACID - automicity, consistency, isolation and durability
- Atomic - something that cannot be broken down into smaller parts; if a group of statement failed in middle, the database should be returned to a state between the exeuction of those statements
- Consistency- some invariant of the database; certain statements about the data that must always be true
- Isolation - cocurrently executing transactions are isolated from each other;
- Durability - once transaction has committed successfully, any data it has written will not be forgotten
-
Weak Isolation Levels:
- Read committed: When reading from the database, only see daa that has been commited; when writting to database, only overwrite data that has been commited
- Implementation: for every record that is overwritted, the database remembers both the old commited value and the new value set by the transaction that currently holds the write lock.
- Snapshot Isolation - each transaction reads from a consistent snapshot of the database
- MVCC - milti-version concurrency control, this can also implement read commited, which uses a separate snapshot for each query, while snapshot isolation uses the same snapshot for an entire transaction.
-
|  |
- visibility rules: when a transaction reads from the database, transaction IDs are used to decide which objects it can see and which are invisible.
- At the start of each transaction, the database makes a list of all the other transactions that are in progress at that time. Any wrties that those transactions have made are ignored, even if the transactions subsequently commit
- Any writes made by aborted transactions are ignored
- Any writes made by transactions with a later transaction ID are ignored, either those trnasactions have commited
- All other writes are visible to the application’s queries
- Put another way, an object is visible if both of the following conditions are true:
- At the time when the reader’s transactin started, the transaction that created the object had already committed
- The object is not markedd for delection, or if it is, the transaction that requested deletin had not yet commited at the time when the reader’s transaction started.
- Lost Update: application reads-modify-write some records, if two transactions do this concurrently, one of the modification can be lost, becasue the second write doesn’t include the modification from the first one (the second one clobbered the first write)
- Atomic write operations:
UPDATE counters SET value = value +1 WHERE key = 'foo'not all situation fits in atomic write operations, but when it fits, it is always the best option - taking an exclusive lock on the object when it is read so that no other transaction can read it until the update has been applied
- or force all atomic operations to be executed on a single thread
- Explicit locking- if any transaction tries to concurrently read the same object, that is being written, it is forced to wait until the first read-modify-write has completed
- Automatically detecting lost updates: Both atomic write and Explicit locking are ways to force the read-modify-write cycle happens sequentially;
- this check can be performed efficiently in conjunction with the snapshot isolation
- the application code don’t need to use any specail database feature
- Compare-and-set - allow update to happen only when the value has not changed since you last read it, this doesn’t work if the database allows the WHERE clause to read from another snapshot
- In-replication: lock and compare-and-set doesn’t work well in replication, especially if there are multiple-leader (different version of data may exist), but atomic works well especailly if the replications are communicative
- Write-skew - two transactions read the same objects and then update some of the objects (if update them same object, then it’s a diry write or lost update)
- Most of the ideas above doesn’t work well to solve write-skew
- atomic works on single object, this involves multiple objects
- automatic detecting needs to know the constaint
- writting constraint on multiple objects is not always supported
- explicit lock is the second-best option (lock the record for update)
- the effect where a write in one transaction changes the result of a search query in another transaction, is called a phantom
- materializing conflicts: it takes a phantom and turns into a lock conflict on a concrete set of rows that exist in the database
-
Serializability: the strongest isolation level, it gurantees that even though transactions may execute in parallel, the end result is the same as if they had executed one at a time
-
Serializable Snapshots Isolation (SSI): a combination to tackle cons of the previous solution - seializability ( don’t perform well), serializability (don’t scale well), weka isolation (prone to race condition - write skew, lost update, phantom )
- Pessimistic vs. optimistic concurrency control:
- Pessimistic - if anything can possily go wrong, than better wait for it to end (two phase lock, serial execution)
- Optimistic - instead of preventing, let the transaction happen anyway and hope everything is fine; when a transaction wants to commit, the database checks whether anythign bad happened, if anything bad can happen, abort for retry.
- Premise: a fact that was true at the begining of the transaction
- SSI shouldbe alble to detect when the Premise is outdated
- Detecting reads of a stale MVCC object version - database will track all the transactions being ignored based on the visibility rule; when the transaction wants to commit, database will abort the transaction if the previously ignored transactions has been committed.
- Wait until it’s ready for committing because if the transaction doesn’t involve write, there is no need to abort Detecting writes that affect prior reads
- Database needs to track when a transaction ignore another transaction’s writes due to MVCC visibility rules
- This is like 2 phase lock, but instead of blocking the other transactions, the transaction that modifies the data will simply notify other transactions that the data they read may be outdated
Batch Processing
- MapReduce - like a unix process, failry brut-force but effective, a programming framework with which you can write code to process large datasets in a distributed filesystem like HDFS
- Steps of MapReduce:
- Read input
- Map each key
- Sort them by key, so adjacent key are put together
- Reduce smae keys

- Shuffling - after the mapper finishes reading the input file and writting its sorted output files, the scheduler notifies the reducers taht they can start fetching the output to the mapper
- Workflow - map reduce job can write to a storage which the next job can pick up the data from this storage directory
- Reduce-side Join and Grouping
- Sort-merge joins: mapper output is sorted by key, and the reducer merge together the sorted list of records from both sides of the join
- Group By: All records with the same key form a group, and perform some aggregation within each group; the mapper should use the grouping key to sort the key-value pair
- Data Skew: identify hot-key and break it to two stage MapReduce
- First stage, randomly send to reducer
- Second stage, bring them back together
- Map-side join
- There are some safe assumption of the input that can be made - no sorting or reducing
- To join a large dataset to a smaller dataset - broadcast hash join
- the smaller dataset can be read in to mermory hash table , so the mapper can simply scan thru the large dataset and perform lookup in the hashtable
- Partitioned Join - the two sides of the data has the same number of partitions with records assigned based on the same key and same hash function
- Map-side merge sort - if the data are not only in the same partition but in sorted order as well, it can perform the merge which normally took place on the Reducer
- HDFS - a hadoop implementation of the Google File System
- A NameNode serving meta data
- A daemon process running on each machine to expose a network service that allows other nodes to access file stored on this machine
- FIle blocks are replicated into different machines to prevent data loss
Stream Process
- Event: The input is event a small, self-contatined, immutable object containing the details of something that happened at some pooint in time
- related events are usually grouped into a stopic or stream
- producer produced the data while consumer use it
- Messaging System:
- Direct messaging form producer to consumer - the applicatiopn code needs to be aware of the potential messaging loss
- Message broker: serve like a database, for which consumer and producer can connected as client
- Multiple consumer:
- Load balancing : each message is delivered to one of the consumer, this is useful when the message is expensive to process
- Fan-out: message is sent to all the consumers
- Redlivery - when the consumer failed, the producer redeliver the message
- reorder - when redelivery is combined with load balancing, the message are not delivered in the same order as they were sent by producer; this is a problem when the order of the message matters
- Log-based: for each partition, the broker assisngs a monotonically increasing sequence number or offset to every message; the messages in a partition is ordered, while the order among different partitions are not guranteed